October 3, 2022 • 11 min read
by Simon Meng, mp.weixin.qq.com • See original
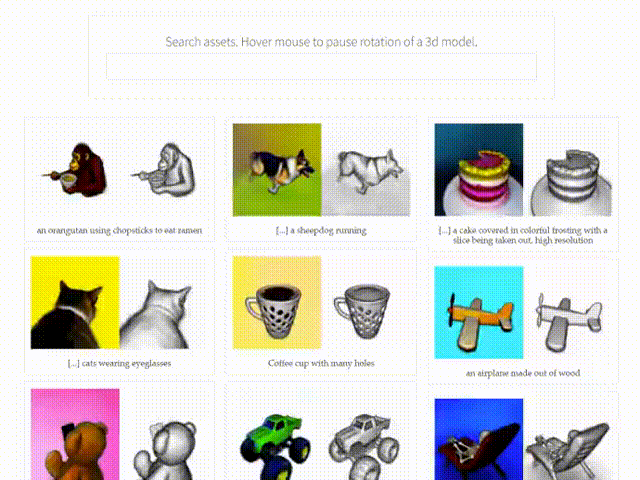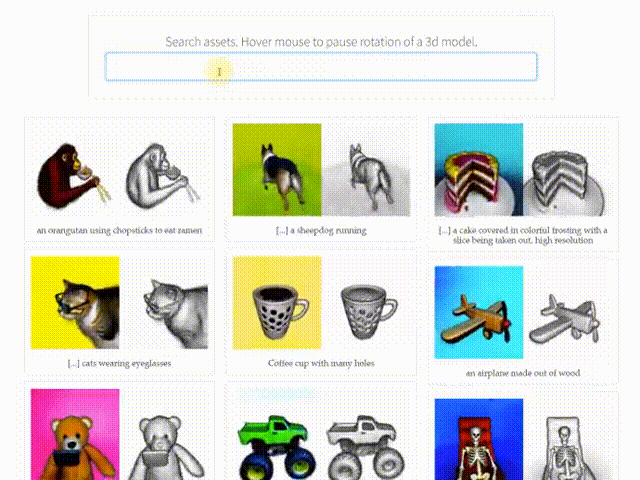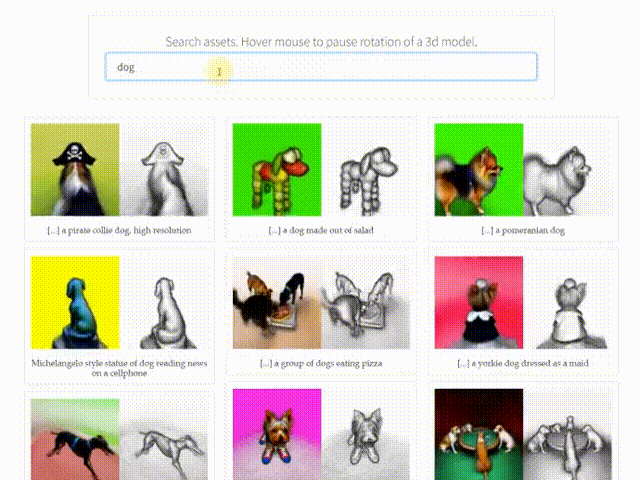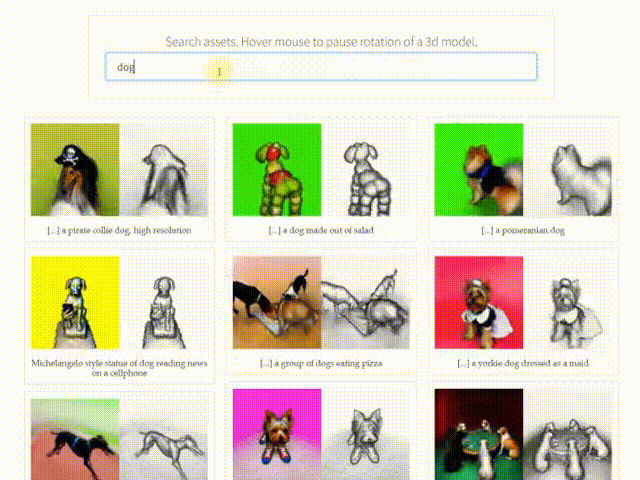
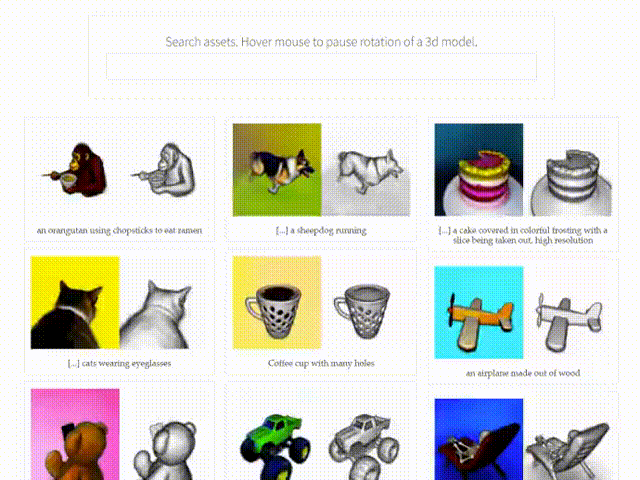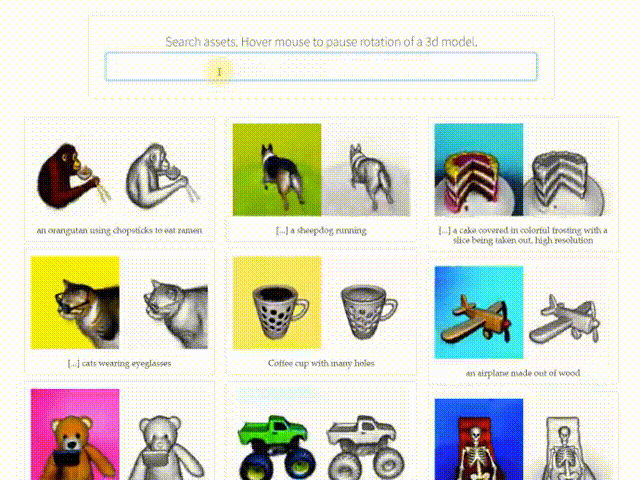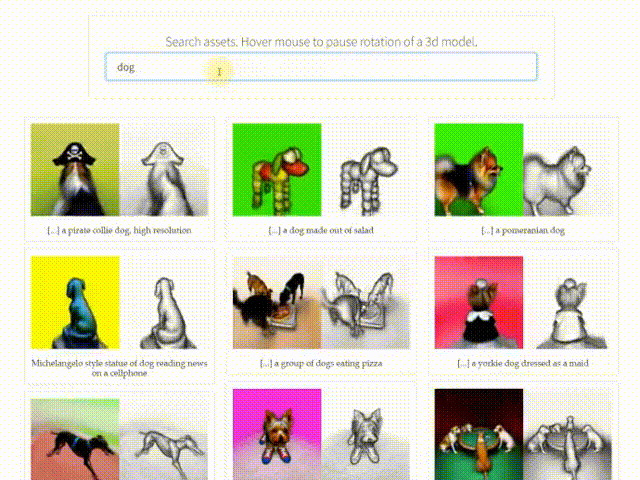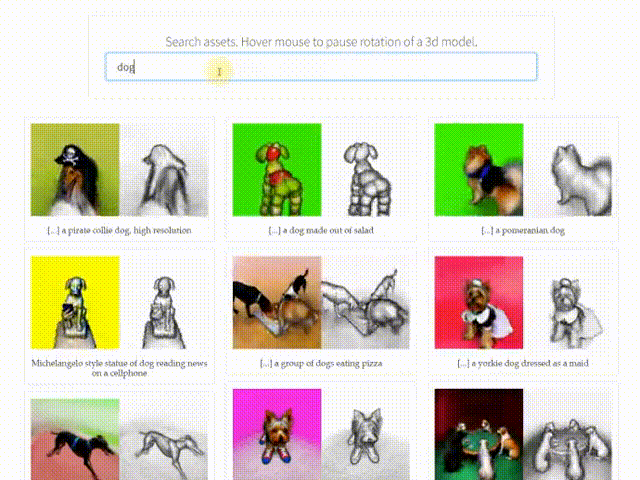
A few days ago, a well-known Weibo influencer, @Simon_阿文, publicly asked me to explain the technical principles behind the latest text-to-3D model AI algorithm, DreamFusion (see the image below). After spending a considerable amount of time, I finally managed to put together a non-expert explanation. I also compared it with the principles of the Dreamfields3D tool I released earlier. I welcome any corrections from the experts!
Conclusion First:
DreamFusion and Dreamfields3D both use underlying technology based on Dream Fields (notice the similar names? Yes, these papers share several authors), which is built on NeRF (Neural Radiance Fields) for constructing 3D objects. The difference is that the earlier Dream Fields used CLIP to guide NeRF. However, since CLIP is not an image generation model but rather a model that judges the similarity between images and text, using CLIP for image generation was somewhat limited. In DreamFusion, the guiding model for NeRF was replaced with Imagen, a diffusion model released by Google, which claims to surpass DALL·E 2 in text-to-image tasks. With Imagen's superior image generation capabilities, along with some fine-tuning and enhancements, DreamFusion achieves better 3D generation results. However, because Imagen has not been open-sourced, it remains uncertain when DreamFusion, which uses Imagen, will be open-sourced (no open-source plans have been announced yet; it might be possible to replace Imagen with Stable Diffusion, which could potentially yield even better results, and this could be a direction for future exploration).
If you want to thoroughly understand the principles of DreamFusion, get ready for a detailed read, as I need to cover four main topics: NeRF, Dream Fields (NeRF + CLIP), Diffusion Models, and DreamFusion.
First, NeRF:
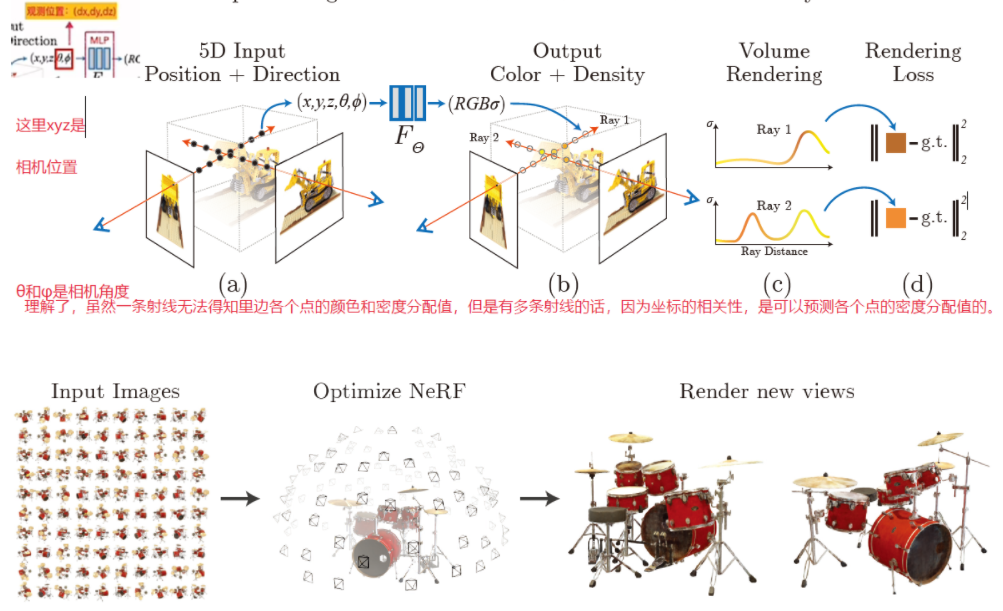
NeRF (Neural Radiance Fields): Based on volume rendering, NeRF can be simply understood as a 3D space matrix with many points, each having different opacity (density) values. Fully transparent points are ignored, while points with some opacity (fully or partially opaque) form a 3D field. This 3D field, when viewed from different angles, presents different colors, representing various 3D objects. The density and color of these points are encoded using a multi-layer MLP (Multilayer Perceptron) neural network, which means they can be trained. Essentially, if we can "tell" NeRF whether the rendered image is closer to or further from what we want, NeRF can iteratively adjust to produce the desired output.
In traditional NeRF, how do we make NeRF represent the object we want? The most straightforward way is to take pictures of a real or already modeled object from different angles (as shown in the image above with the toy excavator and drum set), and then input these images along with the camera poses (XYZ coordinates and rotation angles) into the neural network. The network can then render images based on the given camera poses, compare them with the real images, and iteratively learn to predict a scene as close as possible to the existing object.
Next, Dream Fields:
As you may have noticed, traditional NeRF can only reconstruct existing objects because it requires a reference (either a real object or a digital 3D model). So, can we generate 3D objects without images, using only text? This is where the familiar CLIP pre-trained model (a cross-modal model that connects text and images) comes in, as used in Dream Fields (see the image below).
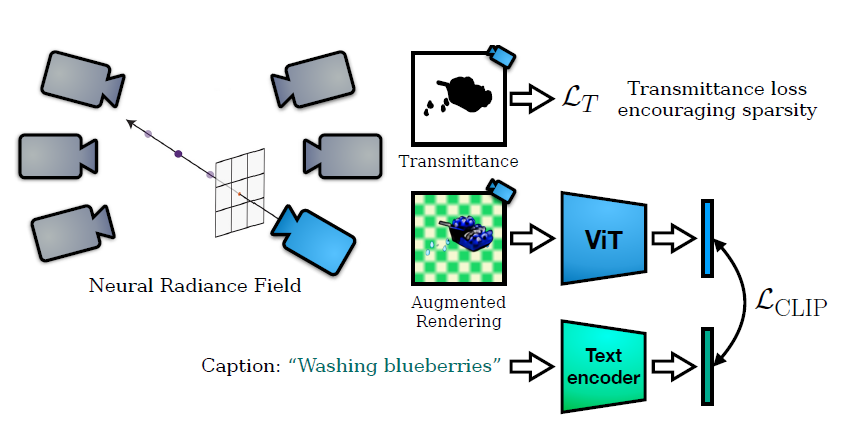
The principle of Dream Fields is quite simple: the user inputs a descriptive text, which is then fed into CLIP. For each camera pose, an image is generated, and this image is also input into CLIP. CLIP then determines whether the generated image is getting closer to or further from the user's text description. This iterative process tunes NeRF, making the generated 3D object gradually align with the text description understood by CLIP.
Building on Dream Fields, DreamFusion replaces CLIP with Imagen, a diffusion model capable of generating images from text. Intuitively, the process should be: input a text, let Imagen generate the corresponding image, and then compare this image with the one rendered by NeRF at a certain camera pose to see if they are similar. However, this is not feasible because, with diffusion models like Stable Diffusion, even if the text prompt is exactly the same, the generated images can be completely different due to the presence of random Gaussian noise (seed). Since we cannot use the same image as the "correct answer" for different views, and Imagen cannot provide geometrically consistent, continuous images from different angles, more advanced methods from diffusion models are needed, which is the most challenging part to understand.
Diffusion Models:
To explain this part, we need to briefly cover the basic principles of diffusion models. Here, we only need to know two things.
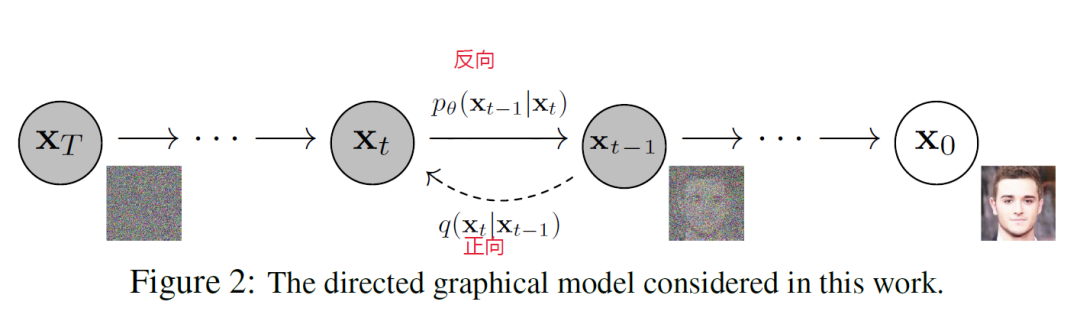
First, during the training of a diffusion model, a real image \( X_0 \) is gradually added with Gaussian noise (from step 0 to step t; the noise addition is a direct calculation, not requiring AI) until a noisy image \( X_t \) is obtained (the forward process). Then, the model is trained to predict what kind of noise was added to make the image so blurry, and then remove the predicted noise from the current \( X_t \) image, step by step, until it returns to a clear image \( X_0 \) (the reverse process).
The key to the success of the diffusion model is the AI's ability to predict the noise \( \varepsilon_{\theta}(x_t, t) \) that was added to the noisy image \( X_t \) and match it with the actual noise \( \varepsilon \) that was added. The mathematical derivation of how to learn denoising from the noising process is complex, but the key point is that the AI aims to minimize the difference \( || \varepsilon_{\theta}(x_t, t) - \varepsilon || \). If the difference is small, the denoised image \( \hat{X}_0 \) will be closer to the original image \( X_0 \).
Back to DreamFusion:
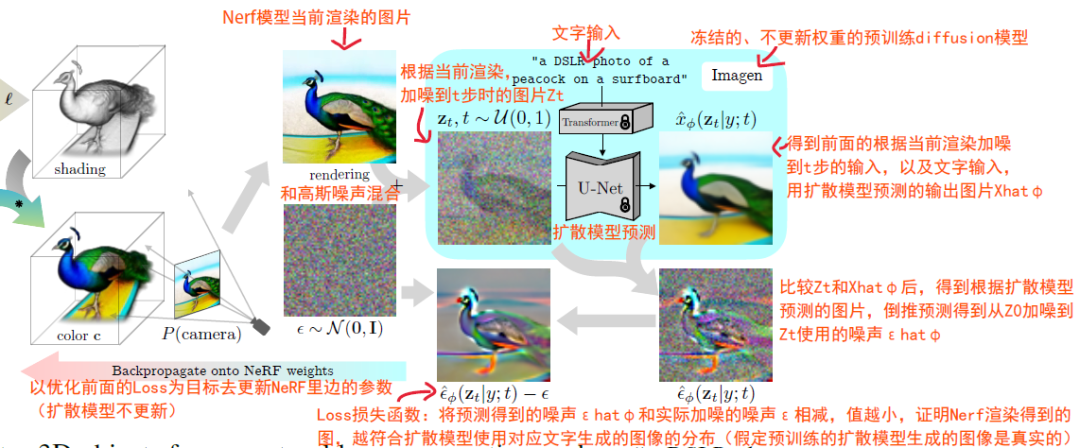
If you've understood this part (if not, read it again; this is the simplest way I can explain it. If you still don't understand after two reads, you have two choices: 1. go and learn the relevant math and AI knowledge, or 2. do something else and come back later. The world is big, and life is long. Let's return to the explanation of DreamFusion.
DreamFusion essentially borrows the model optimization method from diffusion models (i.e., minimizing \( || \varepsilon_{\theta}(x_t, t) - \varepsilon || \)) to ensure that the distribution of images rendered by NeRF from different camera poses, based on a text input, matches the distribution of images generated by the Imagen model from the same text (note that this is about the consistency of the distributions, not exact matches; think of it as the semantic or feature consistency of the two sets of images). The flowchart above (zoom in for more details) outlines the steps, which I'll briefly explain here.
First, NeRF renders an image at a predetermined camera pose, and this image is mixed with Gaussian noise \( \varepsilon \sim \mathcal{N}(0, I) \) to create a noisy image \( Z_t \). Then, the noisy image and the text information \( y \) (e.g., "a DSLR photo of a peacock on a surfboard") are input into the pre-trained Imagen model to get a denoised image \( \hat{X}{\theta}(Z_t | y; t) \). This denoised image is not used directly but is compared with the noisy image \( Z_t \) to determine the predicted noise \( \hat{\varepsilon}{\theta}(Z_t | y; t) \) that Imagen removed.
Since the added noise \( \varepsilon \) is known, we can compare the predicted noise with the actual noise. The key inference is that if the distribution of images generated by NeRF matches the distribution of images generated by Imagen from the text, the added noise and the predicted noise \( \hat{\varepsilon}_{\theta}(Z_t | y; t) \) should also match.
Thus, the goal is to minimize \( || \hat{\varepsilon}_{\theta}(Z_t | y; t) - \varepsilon || \) while keeping the Imagen model parameters frozen, and iteratively train the NeRF parameters to make its generated images increasingly consistent with the distribution of images predicted by Imagen from the text. Additionally, DreamFusion employs various enhancements on the images rendered by NeRF, which I won't go into detail here.
This is a non-expert explanation from a programming novice. I welcome any corrections, and please be gentle with your critiques!
References:
- Explanation of Diffusion Models: https://zhuanlan.zhihu.com/p/449284962
- Dream Fields: https://ajayj.com/dreamfields
- DreamFusion: https://dreamfusion3d.github.io
- 作者:Simon Shengyu Meng
- 链接:https://simonsy.net/article/3DGEN-2022-en
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章

I have open-sourced an AI bionic product generator: 3D Bionic Designer

I have open-sourced an AI bionic product generator: 3D Bionic Designer

How I Used AI to Create a Promotional Video for Xiaomi's Daniel Arsham Limited Edition Smartphone

The 2022 Venice - Metaverse Art Annual Exhibition: How Nature Inspires Design

The Basic Principles of ChatGPT

The Correct Way to Unleash AI Creation: Chevrolet × Able Slide × Simon Shengyu Meng | A Case Study Review of AIGC Commercial Implementation