April 23, 2023 • 3 min read
Yesterday, I suddenly thought about checking out the underlying technology of ChatGPT and how it differs from the (less effective) NLP language models that came before. I found an article that is relatively easy to understand: ChatGPT Principle Analysis
For your convenience, here's a brief summary:
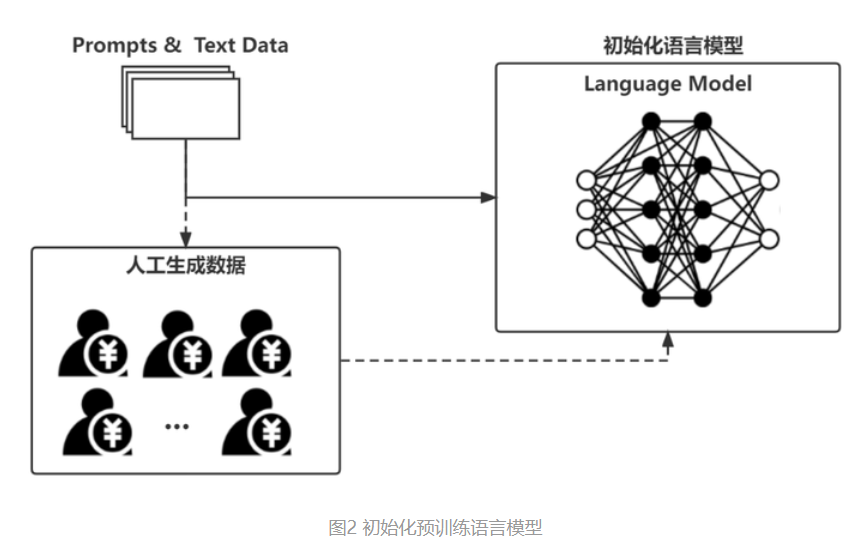
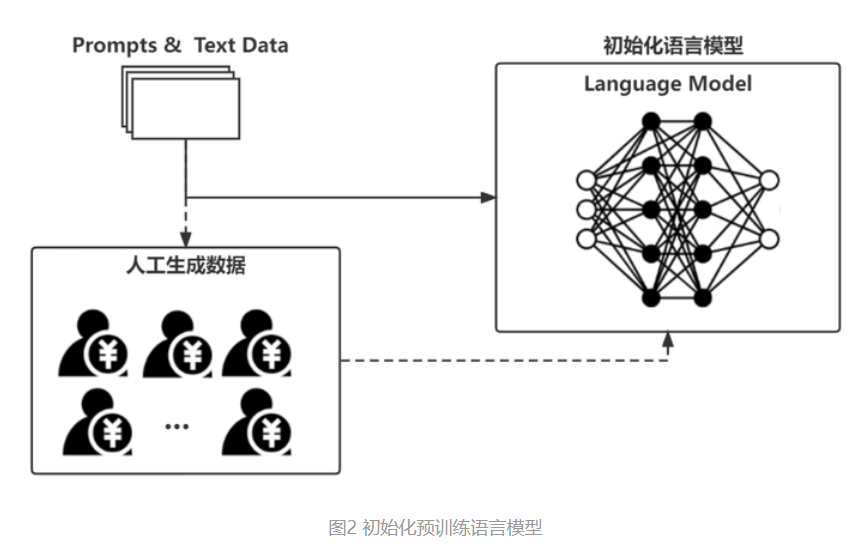
▶1. Traditional language models are trained on paired text datasets for specific tasks. For example, if you want to train a Chinese-English translation model, you need a corresponding paired dataset of Chinese and English texts, and then train the neural network to map between the two. This training method has two issues: it can be difficult to find large enough datasets for many tasks, and the trained model can only be adapted to a single task.
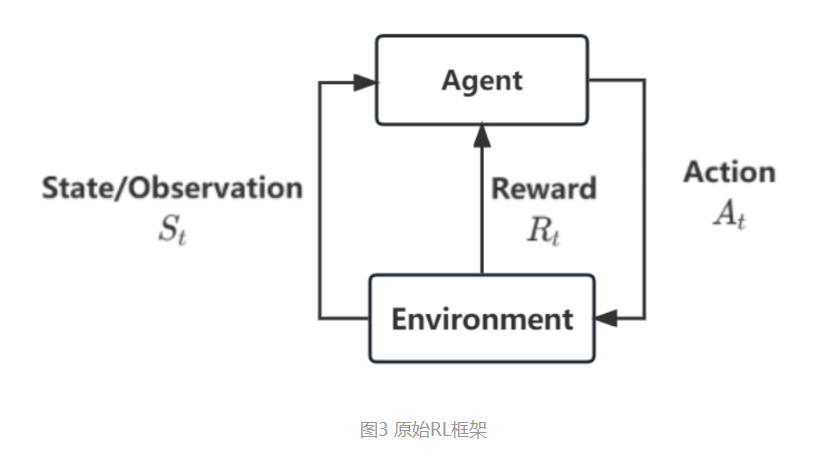
▶2. OpenAI's GPT-3+ model, on the other hand, uses a "self-supervised" training approach.
In simple terms, we don't need paired training sets; instead, we can use any unlabelled text material for training. During training, some of the text content is randomly "masked," and the model predicts the masked content based on the context (the surrounding text). The predictions are then compared with the original text, allowing for self-supervised learning. This way, a vast amount of text data can be used for training. As a result, ChatGPT seems to know a lot because during training, there were no specific requirements for the form of the text material (only quality), so it was fed a wide variety of content (and the AI really does learn from what you give it!)
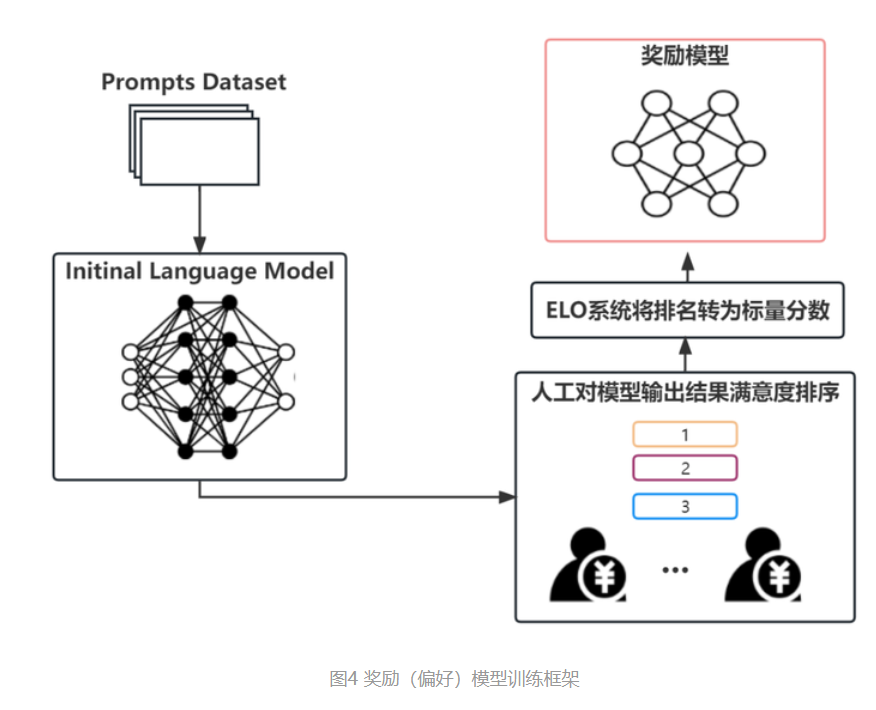
▶3. So, how do we adapt this self-supervised, large language model to specific tasks? This is where RLHF (Reinforcement Learning from Human Feedback) comes into play. Essentially, we can create a smaller, task-specific dataset with input and corresponding optimal answers (such as a Chinese-English translation dataset or a customer service Q&A dataset, which can be collected or created, requiring human involvement). We then combine this with a reward network to fine-tune the existing large model. The goal is to have the large model, when given a specific user input, produce an answer close to the optimal one, while still adhering to the probability distribution constraints of the original large model. This process, known as alignment, allows us to adapt the high-performing, self-supervised large model to various downstream tasks at a lower cost.
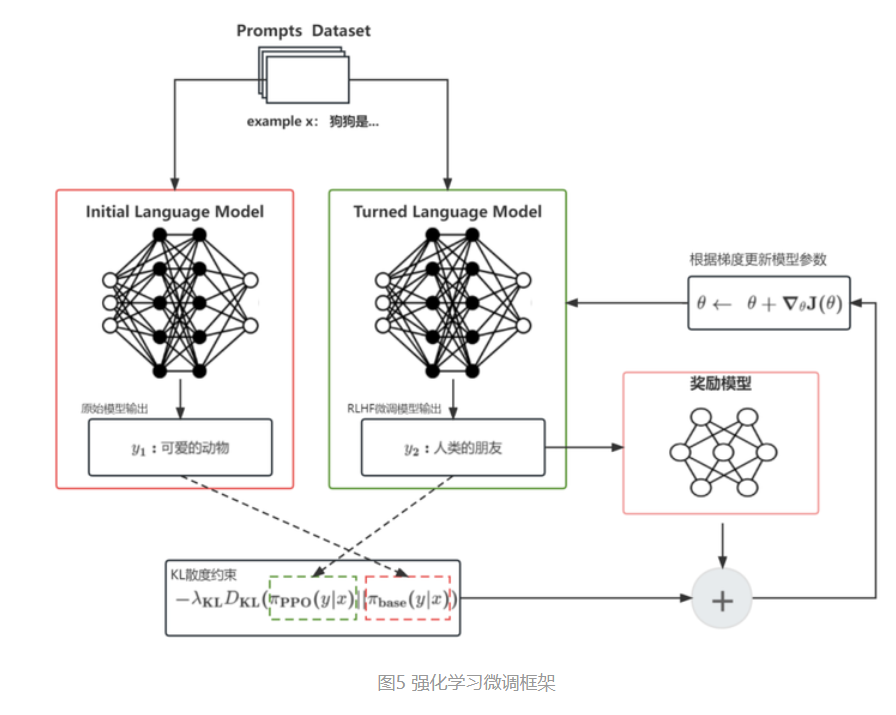
▶4. Finally, in the case of ChatGPT, it essentially fine-tunes and aligns the originally trained large model on all corpora using question-answer pairs (though the actual process is more complex). Therefore, when we ask a question or provide a prompt, it generates a response based on two conditions:
- The response must be in the form of answering the question, not just completing the context (unless specifically requested). This capability is gained from the subsequent model alignment.
- The response must be relevant to the content of the question. This capability is inherited from the original large model trained on a massive corpus.
- 作者:Simon Shengyu Meng
- 链接:https://simonsy.net/article/about-GPT-en
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章

How I Used AI to Create a Promotional Video for Xiaomi's Daniel Arsham Limited Edition Smartphone

The 2022 Venice - Metaverse Art Annual Exhibition: How Nature Inspires Design

From Hand Modeling to Text Modeling: A Comprehensive Explanation of the Latest AI Algorithms for Generating 3D Models from Text

The Correct Way to Unleash AI Creation: Chevrolet × Able Slide × Simon Shengyu Meng | A Case Study Review of AIGC Commercial Implementation

Beyond Appearances - CVPR 2024

Andrew Ng's LLM Short Course Notes 1: ChatGPT Prompt Engineering for Developers