September 25, 2022 • 7 min read
by Simon Meng, See original
Today's article is based on my interview with Quantum Bit, slightly modified (as a loyal reader, this collaboration feels dreamlike!).
Also, I’m excited to announce the demo video for the updated beta v0.6 version of Dreamfields-3D. This update utilizes random camera angles (focal lengths) during training, enhancing the rendered images through random processing before feeding them into CLIP for loss function calculations. This visually seems to improve training stability and slightly enhance generation quality (though no specific ablation experiments were conducted). Detailed usage and program links can be found below!
Text-to-3D! A Architecture Student, Calling Himself a Programming Novice, Creates a Colorful AI Art Tool
Hengyu from A-Fei Temple
Quantum Bit | QbitAI WeChat Official Account
AI artists are advancing their techniques—
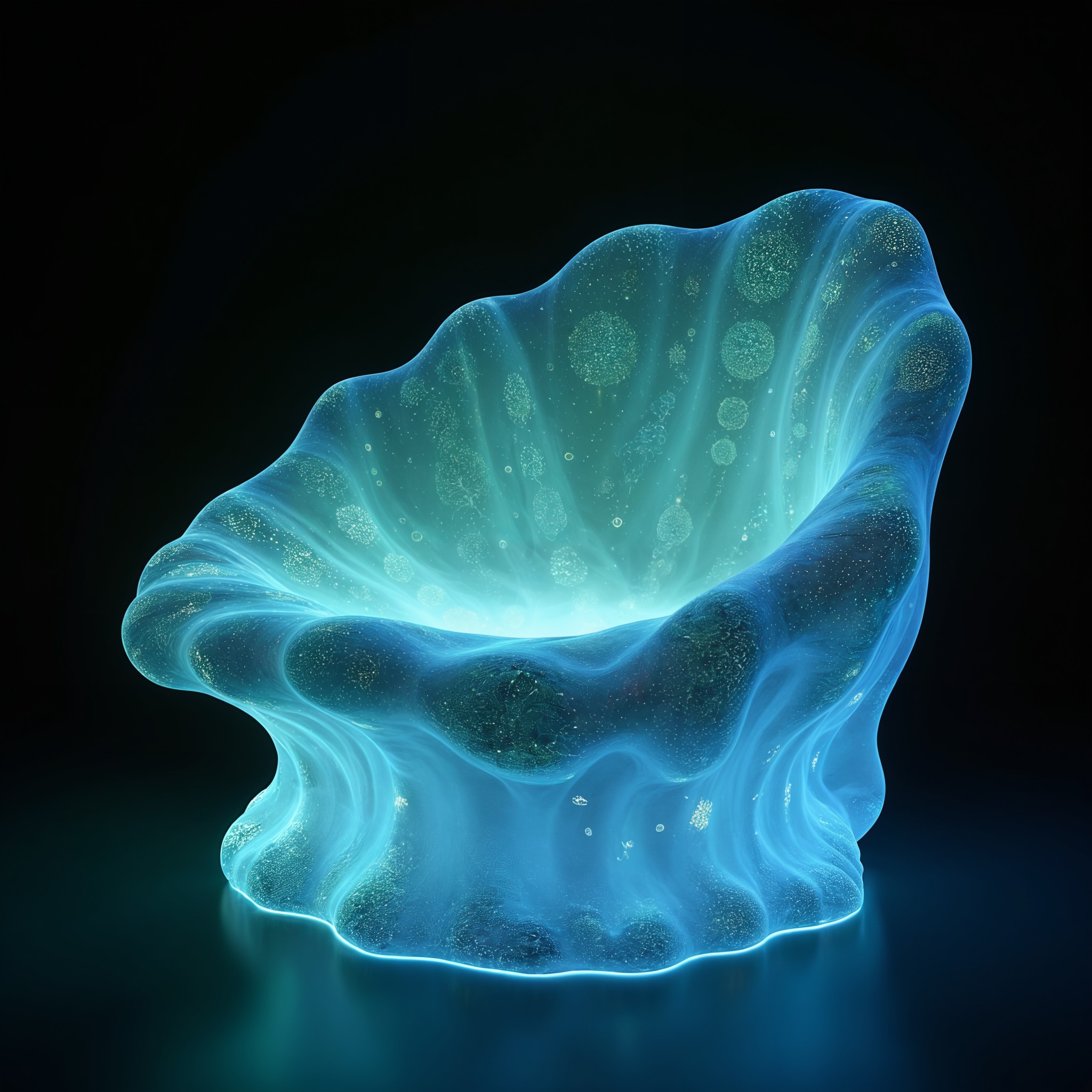
With just a sentence or an image, you can generate 3D models, surround videos, and NeRF instances.
And it’s colorful!
Input "a beautiful painting of a flowering tree by Chiho Aoshima, long shot, surrealism," and you instantly get a video of a flowering tree like this, along with a roaming animation of the exported 3D model lasting 13 seconds.

This text/image-to-3D generation AI is called Dreamfields-3D, created by a PhD architecture student who describes himself as a programming novice.
The demo has been shared on Weibo and Twitter, and many netizens are eager for the beta testing:
Now, the tool is open-source, and you can run it on Colab.
Let’s get started!
Dreamfields-3D is very user-friendly, needing just three steps. Here's how to play online on Colab.
First, check your GPU and connect to Google Drive.

Next, launch the tool and install dependencies.

Then, define some necessary functions, and you can train and test on Colab!
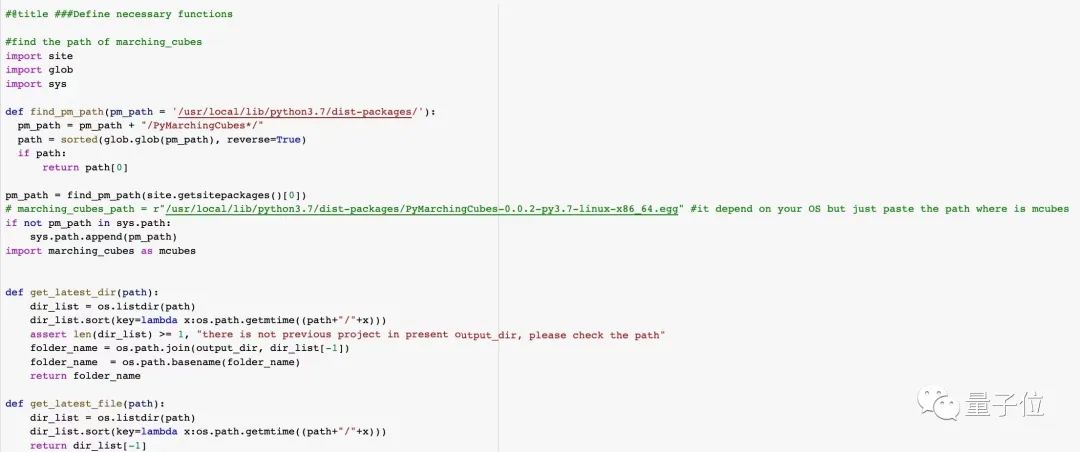
When playing, you'll need to input parameters. Output formats include video and mesh, with the model formats being obj and ply with vertex colors.

Everything is ready, so let's begin!
Try inputting “a cyberpunk flying neon car, in the style of Greg Rutkowski and Simons Daling, long shot, CGsociety, unreal engine, epic game”?
You’ll receive a surprisingly cyber car video.

If you are a fan of "Spirited Away" and want to create a Ghibli-style video.
No problem! Input “an illustration of a beautiful sky city, Studio Ghibli, ArtStation, 8k HD, CGsociety,” and voilà!

Some users couldn't wait to try it and created a small computer.
Of course, amidst the amazement, some users expressed hopes for further improvements in Dreamfields-3D.

(Simon: The above friend probably just didn’t train it well!)
In addition to text input, Dreamfields-3D supports images as prompts.
However, the current version still needs improvement. Inputting images can easily lead to overfitting. Simply put, if you feed it a front image of a car, the generated 3D video might depict the car's front on all four sides...
Those eager to play with image inputs may have to wait a bit longer.
Given the current state, the creator expressed future improvement goals on GitHub:
- Using different CLIP models for training simultaneously.
- Applying image prompts only in specified directions. In the future, constraints on image angles may be added, such as referencing the image only when input images are at the same angle.
- Reading existing 3D meshes as NeRF instances, then modifying them through text/image prompts.
- Reducing GPU RAM usage during training.
(But the creator mentioned he's a programming novice, so further improvements cannot be guaranteed.) doge
Based on Google Dreamfields-Torch
The creator comes from an architecture background and mentioned that Dreamfields-3D is an optimization of Dreamfields-torch from a creator’s perspective, with most of the code work derived from the upstream Dreamfields-torch and Dreamfields.
To introduce, Dreamfields comes from Google, characterized by its ability to generate 3D images from simple text without photo samples.

When generating 3D scenes, the Neural Radiance Field (NeRF) model scheme is typically used.
NeRF is capable of rendering realistic scenes but requires many 3D photos to achieve 360° visual reconstruction.
In contrast, Dreamfields generates 3D models without needing photos, because it is based on NeRF 3D scene technology, utilizing OpenAI’s CLIP cross-modal model to assess the similarity between text and images. By inputting text, it guides the construction of 3D models and stores them through neural networks.
Dreamfields-torch is a modified PyTorch implementation of Dreamfields, primarily changing the original NeRF backend to a PyTorch version of instant-ngp.
Based on this, Dreamfields-3D essentially operates using CLIP + NeRF.
Author Bio
The author, Meng Shengyu (Simon Meng), is a PhD student in architecture at the University of Innsbruck (UIBK), Austria.
He holds a Master's degree in architecture from University College London (UCL) and is currently a teaching assistant and invited reviewer for technical courses at UIBK and UCL, conducting interdisciplinary research in architecture, art, AI, and biology.

The creator has been following AI image generation since June and July last year.
He noticed that many groundbreaking technologies, such as clip guide diffusion and disco diffusion, were developed by cross-disciplinary individuals (artists) with coding knowledge.
After Google released Dreamfields at the end of last year, he was inspired to create 3D outputs with it.
Subsequently, upon obtaining the animation, he performed super-sampling enlargement and frame interpolation using AI, then exported the frames to a standard multi-view reconstruction software (similar to Colmap), successfully reconstructing a mesh (a model map restored from 3D model data).

He shared the mesh on Twitter, leading to a contact from the original author of the Dreamfields paper, Ajay Jain, who welcomed him and encouraged ongoing optimization updates—even though at that time he was using standard multi-view image reconstruction software, not a code-based approach.
Last month, he created a Colab version based on Dreamfields-torch, and this month opened it on GitHub for everyone to enjoy.
Moreover, this is now a brand-new version based on Marching cubes!
GitHub link:
Colab link:
Reference Links:
- 作者:Simon Shengyu Meng
- 链接:https://simonsy.net/article/dreamfields-3D-en
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章

Vibe Coding: Fundamental Concepts

I have open-sourced an AI bionic product generator: 3D Bionic Designer

A Book from the Sky

I have open-sourced an AI bionic product generator: 3D Bionic Designer

How I Used AI to Create a Promotional Video for Xiaomi's Daniel Arsham Limited Edition Smartphone

Works Series - Dimensional Recasting