November 27, 2023 • 8 min read
by Simon's Daydream, See original
Introduction: (The full text is 1000 words, and it takes about 3 minutes to read.) This article will touch on some computer-related terminology (not too much), and by the end, you will have a general understanding of the development patterns of AI-based 3D generation models.
- Let’s start with the conclusion: Recently, several 3D generation models have coincidentally adopted the approach of simplifying 3D model problems into 2D model problems. Historically, successful simplification of a problem often indicates that the problem is (almost) solved.
Instant3D, One-2-3-45++, and Wonder3D are a few recent 3D generation models that perform better. Their commonality is that they maximize the use of prior information from 2D stable diffusion models.
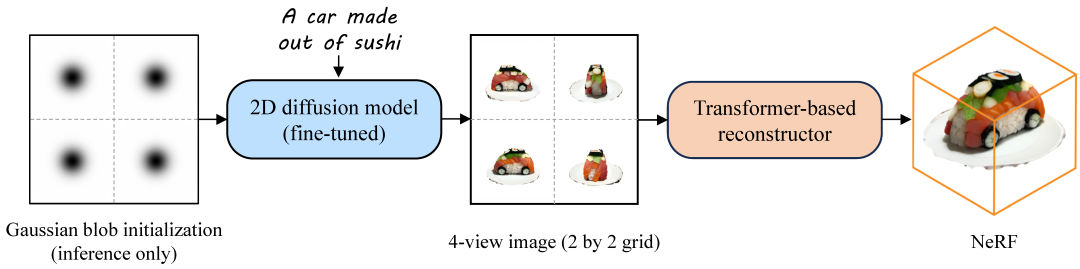
- Instant3D: Uses a fine-tuned stable diffusion model to generate feature-continuous four views based on input text/images, and then reconstructs the 3D model using NeRF from these four views.
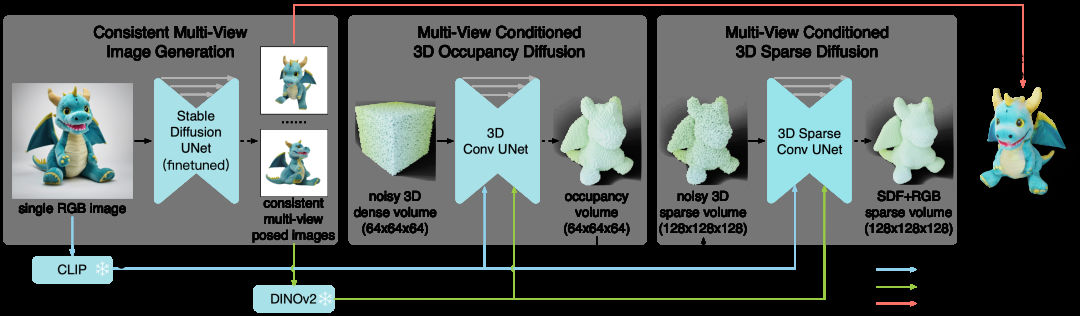
- One-2-3-45++: Similar to the previous model, it uses a fine-tuned SD model to input a monocular image to obtain feature-continuous multi-view images, then reconstructs the 3D model using a 3D convolutional neural network and SDF.
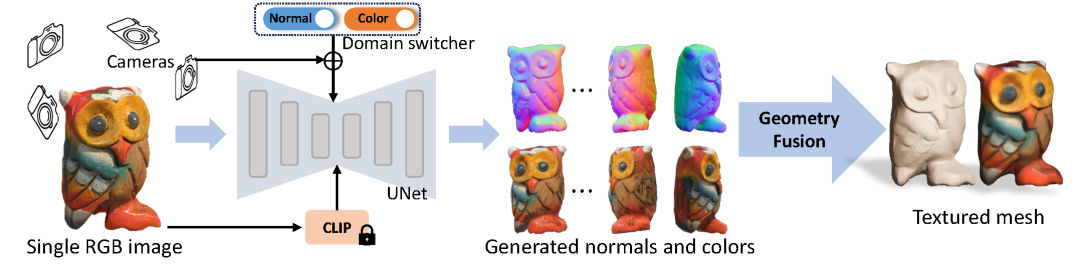
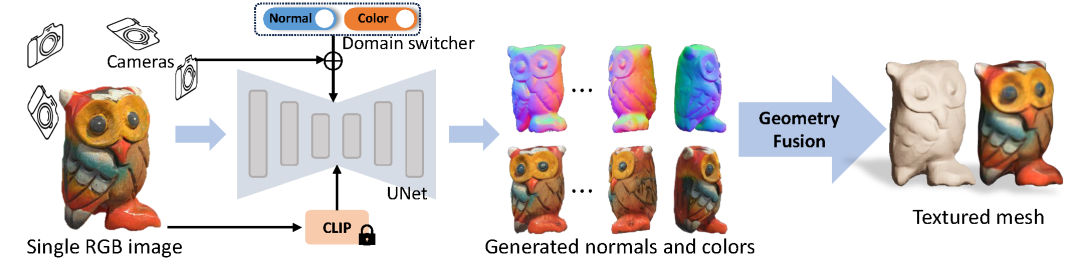
- Wonder3D: Based on the stable diffusion model, it fine-tunes a model capable of outputting feature-continuous multi-view RGB images and normal maps simultaneously, and finally reconstructs the 3D model using a normal fusion model.
These algorithms share the common advantages of speed (achievable in 1-2 minutes on a single GPU) and reasonable quality. Compared to earlier 3D generation algorithms, especially ProlificDreamer, Zero-1-to-3, DreamFusion, and shap-e before DreamGaussian (all released within the past year), there has been a significant improvement either in speed or quality.
This indicates that effective utilization of 2D diffusion models has led to a leap in performance for 3D generation models over the past two years. It is precisely the breakthrough development of 2D diffusion models that has enabled the simplification of 3D generation problems.
Illustration of RNN (Recurrent Neural Network)
However, this phenomenon is understandable. It’s similar to natural language processing (NLP), a classic task that was previously attempted to be explained using complex rule-based methods such as semiotics, cybernetics, etc. With the emergence of recurrent neural networks (RNNs), along with the increase in the volume of online text data and computational power, natural language processing was simplified to the "simple" task of predicting the probability of specific upcoming text based on previous input, leading to significant advancements in NLP. Of course, the term "simple" refers to the principle rather than the engineering aspect (the actual large language model is an exceptionally complex engineering feat), but it is this conceptual simplicity that allows for the accommodation of greater complexity in engineering. The structural reliability improvement gives engineering more room for error tolerance.

Example of the ShapeNet dataset
Looking back at 3D generation, earlier 3D generation models were typically based on 3D convolutional neural networks (3D CNNs), 3D generative adversarial networks (3D GANs), or some complex 3D implicit representation methods, but the results were not satisfactory. On one hand, because the results were not that great, there was a lack of unified direction, leading to technical route disputes; on the other hand, the content of 3D databases was lacking: most models were trained on the ShapeNet database, which contains only dozens of categories with over 100,000 models, most of which are chairs. This is why most previous 3D generation papers demonstrated generating chairs—because the quality of generating other items significantly declined... Now, although there is the so-called Objaverse-XL database claiming tens of millions, the actual quality of the models varies widely, and perhaps only less than a million can be used after cleaning, not to mention comparing with the tens of billions of 2D image-text databases.
Intuitively, it is possible to accurately restore the 3D information of a single object from simple text or monocular image input, given sufficient prior support from 2D models. Just as humans can imagine the complete 3D form of an object from text and monocular image inputs, we have seen enough different objects in various 2D projections and accumulated our knowledge. This may also be one of the reasons why Musk firmly supports that pure visual solutions can solve 3D environmental perception and autonomous driving problems.
Therefore, I would like to reiterate my previous judgment: as the capabilities of 2D models continue to enhance, and with everyone's concentrated efforts on applying 2D models to the 3D generation technical route, the generation of individual 3D objects will likely be fundamentally resolved within 1-2 years.
However, this gives rise to another problem—reasonably combining and placing a large number of different types of 3D objects to create coherent and sensible complete 3D scenes according to human perceptual habits.
The importance of this issue arises from some recent thoughts: the quality of current 3D generation models is actually "adequate." Why hasn't there been a strong community spread similar to that which occurred during the peak of 2D generation models (the Disco Diffusion period)?

Abstract yet interesting images generated by Disco Diffusion
- My answer has two parts: The first reason is easy to think of: displaying 3D models is relatively complex and not as easy to store and display as images. The second reason is deeper: what we actually need is not 2D or 3D itself, but the narrative and emotional value brought to us by each modality.
Even if a 2D image is abstract and vague, each picture represents a complete narrative, always providing enough information and associative space. However, the currently AI-generated 3D models exist in isolation and out of context. Only when 3D models are effectively integrated into a complete environment can they bring narrative and emotional value.
So, can we learn reasonable and complex combinations of multiple 3D objects directly from 2D images?
Firstly, intuitively, it is quite difficult. One reason is that the multi-view image data for the same group of complex object combinations is relatively scarce, and the second is that after the objects are combined, they will obstruct each other (some may even be invisible, such as those enclosed internally), making it challenging to restore the accurate 3D combination relationship from 2D images.
Secondly, the relationships between object combinations are a more abstract node relationship, more akin to the graph node relationships seen in protein structure prediction, rather than a simple probability relationship between pixels. This may become a more significant issue in the AI 3D generation field, and it is precisely what we are trying to solve with our self-developed graph network model. If you are interested in our research, you can read the following article:
References:
_Instant3D: https://jiahao.ai/instant3d/?ref=aiartweekly_
_Wonder3D: https://www.xxlong.site/Wonder3D/_
_One-2-3-45++: https://sudo-ai-3d.github.io/One2345plus_page/_
_Objaverse: https://objaverse.allenai.org/_
_ShapeNet: https://shapenet.org/_
_RNN (Recurrent Neural Network): https://zh.wikipedia.org/zh-hans/循环神经网络_
- 作者:Simon Shengyu Meng
- 链接:https://simonsy.net/article/3d-locate-en
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章

AI Programming Tools: An Introduction and Comparison

I have open-sourced an AI bionic product generator: 3D Bionic Designer

I have open-sourced an AI bionic product generator: 3D Bionic Designer

How I Used AI to Create a Promotional Video for Xiaomi's Daniel Arsham Limited Edition Smartphone

The 2022 Venice - Metaverse Art Annual Exhibition: How Nature Inspires Design

The Basic Principles of ChatGPT